

Kali 2021.2 + RPi 4: una pareja perfecta
La unión de la última versión de Kali (2021.2) con la última versión de la Rapsberry Pi (4 Model B) crean la pareja perfecta para tener un dispositivo portátil de pentest.
Todos los profesionales de seguridad necesitamos, en algún momento, desplegar un dispositivo portátil que nos permita probar o analizar vulnerabilidades. Una de las opciones más lógicas es la de usar mini motherboards. Hoy en día existen muchas SBC’s (Single Board Computers) en el mercado. La mayoría de ellas se basan en procesadores ARM. Para la gran mayoría de ellas, existen diferentes distros de Linux, incluyendo Kali.
Experimentos
Si bien he experimentado con algunas otras, la placa que más suelo usar es la Raspberry Pi. Ya escribí sobre algunos experimentos que hice basándome en la RPi. Además de este trabajo, experimenté probando diferentes usos.
Uno de ellos fue el de reemplazar la notebook en un viaje, con algún dispositivo más pequeño y liviano que pudiera entrar el el bolsillo de la mochila. Este es uno de los kits que usé.

Fig. 1 – Mini set de viaje con la RPi3 😉
Ustedes dirán que falta el display, si! obvio! pero hoy en día no encontré hoteles donde no hay aun televisor con entrada HDMI… Así que si bien sólo la podía usar en el hotel, tenía toda la potencia de un Linux en el bolsillo.
Otro de mis experimentos fue el de instalar el Kali completo en la RPi 3. Bueno, se puede, pero no es muy fácil de usar. Recuerden que esta versión, aún la Model B, viene con un máximo de 1GB de RAM. Esto hace que sea algo difícil hacer correr las X. Entonces, si además cargamos alguna aplicación pesada, se vuelve imposible. Memory exhaust por todos lados o, en el mejor de los casos, tiempos de respuesta larguísimos. En especial si la dejamos conectada en un sitio remoto, y queremos acceder a las X vía VNC.
Openvas
Ustedes se preguntarán, qué aplicación necesito sí o sí correr en este hardware sobre las X? Bueno, una de ellas es el Openvas. Los que lo instalaron saben lo quisquilloso que es respecto al acceso remoto. Y si tienen que resolver algo rápido, no pueden estar días instalando, desinstalando y cambiando configuraciones para que funcione.
Por si les interesa, les paso una alternativa para no utilizar el Openvas desde un browser en la misma RPi, sino usando por SSH los comandos de línea del Openvas: el OMP. Como verán, correr un scan desde OMP es un chino. Pero si no hay otra forma de hacerlo, es una solución posible.
Raspberri Pi 4 Model B
Respecto a las limitaciones de hardware, todo se solucionó con la Raspberri Pi 4. El modelo salió a fines de 2018 y con una característica fundamental, la máxima configuración de RAM pasó de los humildes 1GB a 4GB. Además de muchas otras mejoras, en este modelo sí se podían correr aplicaciones un poco más pesadas. Y como verán, mi kit de viaje no cambió mucho…

Fig. 2 – Mini set de viaje con la RPi4 😉
El salto final, hasta hoy, obvio… se dió con la Raspberry Pi 4 Model B. En este caso, la máxima configuración de RAM con la que se puede comprar la placa es de 8GB. Ahora sí!
La empresa, además, apostó a una nueva mejora con la Raspberry Pi 400. Un modelo en el que implantan la RPI4 Model B en un case de teclado logrando esto:

Fig. 3 – Nuevo modelo: RPi400
El lado oscuro
Dependiendo de cómo la vayamos a usar y dónde la vayamos a instalar físicamente, una característica que obligatoriamente debemos tener en cuenta para esta versión es la temperatura. En términos simples, la RPi4 calienta. Es que es pura lógica, una gran velocidad viene con un gran consumo de energía, por lo tanto de disipación de calor.
Es por eso que los mejores gabinetes incluyen coolers, además de ser de aluminio para poder disipar mejor el calor. Yo tengo una Flirc case que, la verdad que disipa bastante bien. En la ofi también probamos la Argon One, que además de disipar bien, viene con un adaptador para sacar todos los conectores por detrás y convierte las 2 salidas de video de mini HDMI a HDMI.
Kali 2021.2
Es muy interesante que este año, todavía no llegamos a la mitad, y ya se liberaron dos versiones, Kali 2021.1 en febrero pasado y Kali 2021.2 el 1 de junio último.
Siendo la distro de seguridad más usada, se puede encontrar que hay versiones de Kali para muchas plataformas:
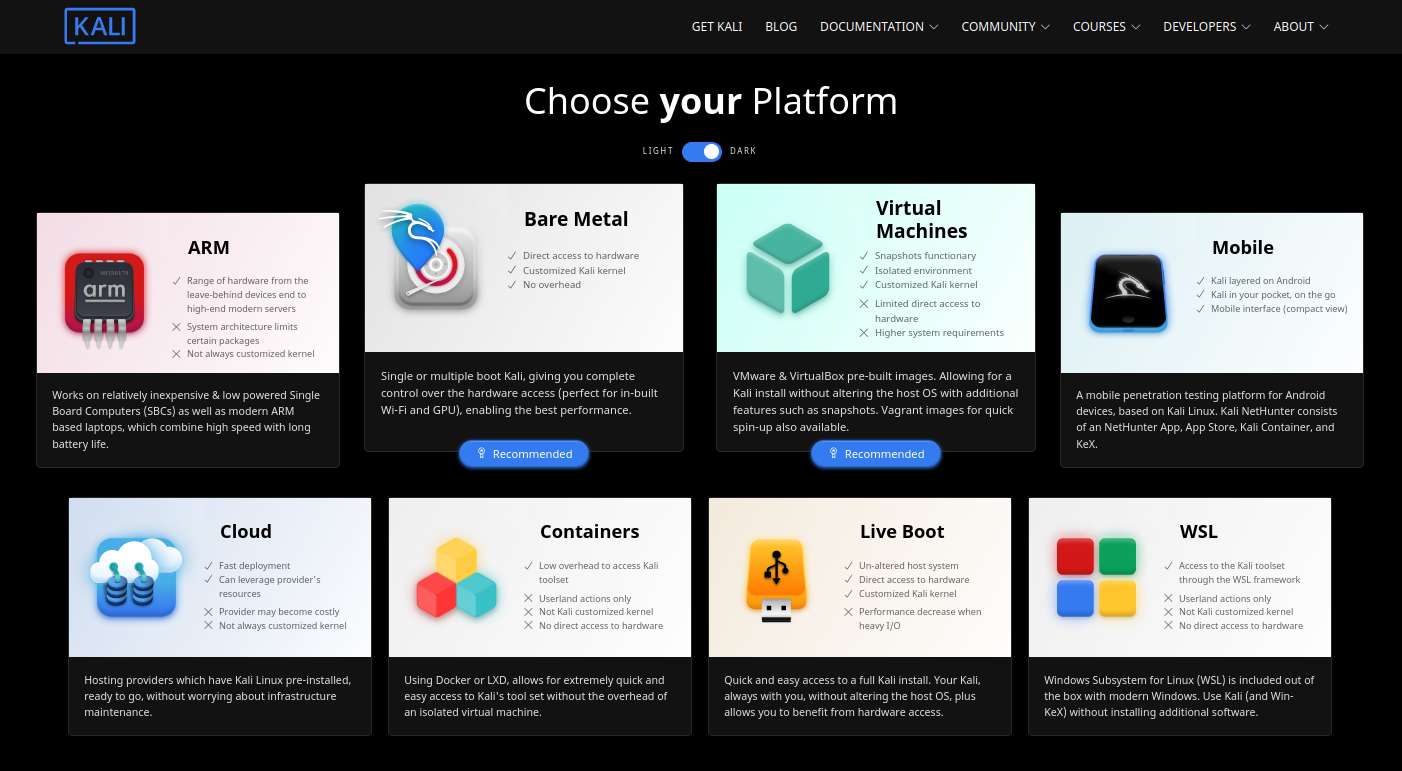
Fig. 5 – Plataformas de Kali.
La que ahora nos interesa en particular es la de ARM:

Fig. 6 – Descargar Kali para ARM.
Esta versión viene con muchas mejoras en general, pero particularmente las que me interesan son las relacionadas con la RPi.

Fig. 7 – Mejoras de Kali 2021.2 relacionadas con la Raspberry Pi.
Una de las que quiero destacar es la de kalipi-config. Si bien hasta ahora existía un raspi-config portado a Kali, estaba bastante limitado y se perdían muchas configuraciones del hardware en esta herramienta. El haber incorporado el raspi-config en forma nativa, nos da muchas más posibilidades.
La otra mejora que incorporan, es la configuración para displays TFT. No se si usar este tipo de displays es muy útil en este tipo de aplicaciones, pero bueno, la posibilidad está.
A probar!
Lo que yo veo como más interesante es que ahora la RPi tiene verdaderamente una potencia superior. Por un lado, la Raspberry Pi 4 Model B es bastante más rápida que la Raspberry Pi 3 Model B. Acá pueden ver los benchmarks. Por otro lado, el incremenetar la memoria máxima de 1GB a 8GB ya va dando otras posibilidades interesantes.
Por el lado de Kali 2021.2 para ARM, al mejorar los drivers para el hardware, juran que su performance sobre RPi subió 1500%… y que el booteo inicial pasó de 20 minutos a 15 segundos…
Bueno, esta pareja parece prometer, así que no queda otra que probar. Trataré de hacer algunas pruebas y pasaré los resultados como update de esta nota.
Hasta la próxima!
Nota por Carlos Benitez













 Fig. 1 – Esfera de Bloch
Fig. 1 – Esfera de Bloch
